들어가며
올해 상반기, 나의 최대 관심사는 무엇보다도 졸업(!!!)이었다. 많은 대학원생들이 으레 그렇듯 예상치 못한 사정으로 졸업이 예정보다 반년 늦어졌고 그마저도 더 늦어지겠다 싶어 모든 우선 순위를 제쳐두고 학위 논문을 준비하게 되었다.
그렇게 1월 말부터 논문을 구상하고 작성하며 시간이 흘렀고, 실험 과정에서 굉장히 많은 시행 착오도 겪었다. 두 번의 발표와 도장을 받기위해 교수님들께 메일을 보내고 돌아다니며 모든 서류 제출을 끝내고 나니 6월이 되어있었다. 그렇게 학위 논문을 모두 제출하고 대학원과 관련된 모든 것을 털어내고서야 드디어 석사(진)이 되었다.
그래도 8월까지는 학생이니만큼 학생 신분의 마지막이 지나기 전에 자축의 의미로 본 포스팅을 작성하기로 하였다. 사실, 2년 반 동안의 지난했던 기간의 회고를 할까도 생각했지만 너무 할 말(못 할 말)이 많아지기 때문에 다소 식상하지만 학위 논문을 작성하면서 정리했던 인공지능의 발전사와 개략적인 개념을 최대한 많은 사람들이 이해할 수 있도록 포스팅에 설명해보기로 했다.
 아..아앗...아니야...!!
아..아앗...아니야...!!
사실, 이 블로그는 루비콘 사람들과 머신러닝 스터디를 진행하며 내용을 정리하기 위한 목적으로 처음 개설했었다. 그래서 이 블로그의 초반에는 지금 할 얘기와 꽤 겹치는 얘기가 많다.(스터디가 오래 이어지지는 않았어서 내용이 많지는 않다.) 아직 많은 포스팅을 하지 않았지만, 당시 글을 썼을 때보다 몇 년의 시간이 지났기 때문에 일종의 리워크로써 본 포스팅을 작성한다.
지금도 부족하지만 이때의 포스팅은 다시 보기 민망하다. 😓
인공지능? 머신러닝?? 딥러닝??? 다 같은 말 아녜요? 🤔
인공지능, 머신러닝, 딥러닝은 IT 및 인공지능 관련 지식이 없는 사람들이 가장 혼동하는 용어다. 대부분 이 세 가지에 대해 동일하게 생각하거나 머신러닝이나 딥러닝이라는 용어를 아직 잘 모르는 사람들이 많다.
간혹 딥러닝을 스스로 학습한다고 말하는 경우가 있는데, 그런 설명이 이해가 안되는 것은 아니지만 오히려 사람들에게 혼동을 줄 수 있기도 하고 모든 딥러닝을 정의하기에 적절한 워딩은 아니라고 생각한다.(Self-Supervised Learning이나 NAS 같은 AutoML이라면 모를까..)
아마도 높은 퍼포먼스를 보이는 방법론들이 딥러닝으로 귀결되고 있으니 용어의 혼동이 온다고 생각한다. 이들을 설명하기 위해 가장 흔하게 사용하는 다이어그램을 나도 한 번 그려보았다.
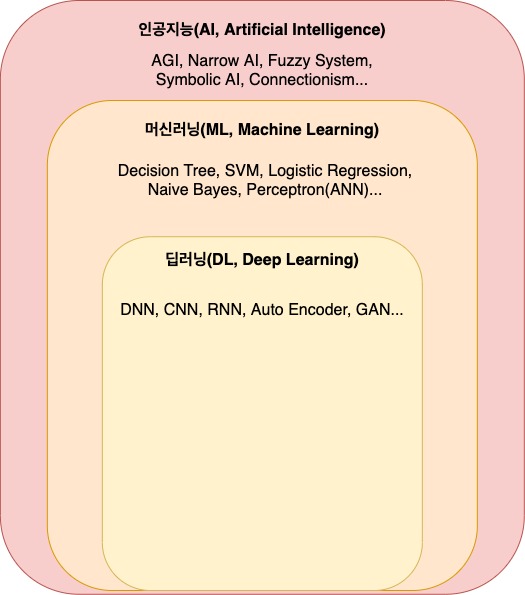 인공지능, 머신러닝 그리고 딥러닝
인공지능, 머신러닝 그리고 딥러닝
아무튼 먼저 인공지능은 머신러닝의, 머신러닝은 딥러닝의 슈퍼셋으로 용어들 간에는 포함 개념을 갖고 있으며 동일한 용어가 아님을 짚고 간다. 각각의 개념을 다시 아래와 같이 설명할 수 있을 듯 하다.(학부 시절, 많은 것을 가르쳐주신 박성호 교수님의 워딩을 레퍼런스한다.)
인공지능(AI, Artificial Intelligence)
인간의 학습능력, 추론능력, 지각능력 등을컴퓨터를 통해 구현하는 포괄적인 개념머신러닝(ML, Machine Learning)
주어진데이터의 특성과 패턴을 학습하고 이를 바탕으로새로운 데이터에 대한 결과를예측, 데이터 마이닝(Data Mining)이 데이터간의 상관관계나 속성을 찾는 것이 주 목적인 반면, 머신러닝은 상관관계를 통해 새로운 데이터의 결과를 예측하는 것에 목적을 두고 있음딥러닝(DL, Deep Learning)
머신러닝의 한 분야이며, 인공신경망(ANN, Artificial Neural Network)의 층을 깊게 하여 설계한딥 뉴럴 네트워크(Deep Neural Network)로 학습하는 알고리즘의 집합
인공지능..? 🙄
인공지능이라고 하면 대부분은 아이, 로봇이나 터미네이터 등에 나오는 기계와 같이 사람과 유사하거나 혹은 사람을 뛰어넘은 것들을 생각하지만, 인공지능이라는 용어 자체는 굉장히 포괄적이다.
사실, 사람이 하는 일을 일부라도 기계로 대체할 수 있으면 그러한 모든 것은 인공지능이다. 그러니까, 학습하는 알고리즘이 아니라 단순히 if-then-else를 늘어놓은 알고리즘으로도 인공지능을 만들 수 있다는 말이다.1
이러한 방법은 퍼지이론(Fuzzy Theory)에 근거한 Symbolic AI(Expert System)2이다. 지금과 같은 대 인공지능 시대가 오기 전에 버튼만 몇 개 눌러주면 손빨래를 하지 않아도 알아서 빨래를 해주는 세탁기와 같은 인공지능 기계(요즘에 말하는 인공지능 세탁기가 아니라)가 실생활에 이미 들어왔었다는 뜻이다.
 대-인공지능 시대를 맞는다.
대-인공지능 시대를 맞는다.
머신러닝..?? 🤯
Symbolic AI은 전문가들의 Knowledge base로 규칙을 만들어 행동 패턴을 모델링(Rule-based Modeling)하는 방법이다. 그러나 전통적인 Symbolic AI는 학습 단계가 없다는 한계점이 있다. 이러한 한계점으로 인해 Task가 복잡해질수록 Symbolic AI으로 높은 성능을 내기는 어려웠고, 이를 대체하기 위해 나온 방법이 머신러닝이다.
대부분의 머신러닝 기법은 Symbolic AI에서 파생된 인공지능 방법론으로 일종의 통계학이다. 다만 Symbolic AI가 전문가의 지식을 하드 코딩으로 규칙을 만들고 이 규칙에 따라 데이터를 입력하면 정답을 출력하는 반면, 머신러닝은 데이터와 통계적 방법을 활용하여 규칙을 도출하는 방식으로 되어있다.
 머신러닝은 블랙박스
머신러닝은 블랙박스
이러한 통계적 모델링(Statictical Modeling) 방법은 데이터를 활용하며, 보통 학습 단계와 추론 단계로 나누어져 있다. Symbolic AI와 통계학을 가장 직관적으로 접목시킨 머신러닝 알고리즘이 Decision Tree가 아닐까 싶다.
러닝이란 워딩이 들어간만큼 방법론에 따라 혹은 Task에 따라 학습의 종류도 나뉘는데, 크게 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning)3으로 구분된다. 후에, 딥러닝이 발전하면서 추가적으로 강화학습(Reinforcement Learning)이라는 카테고리도 생겼으며, 준지도학습(Semi-Supervised Learning) 등도 존재하지만 일반적으로 지도학습, 비지도학습과 강화학습을 가장 큰 카테고리로 보고있다.
지도학습(Supervised Learning)
입력 값과 정답(값 혹은 분포)을 포함하는 학습 데이터(Training Data)를 이용하여 학습하고, 그 학습된 결과를 바탕으로 새로운 데이터(Test Data)에 대해 결과 값을 예측(Prediction, Inference), 지도학습은 학습 결과를 바탕으로 Task에 따라 다시 크게회귀(Regression),분류(Classification)4 등으로 구분비지도학습(Unsupervised Learning)
정답이 없는 입력 값으로만 구축된 학습 데이터를 이용하여 학습하고, 입력에 대한 정답을 찾는 것이 아닌 입력 값의 유사도(Similarity), 패턴(Pattern), 특성(Feature) 등을 학습을 통해 발견하는 방법을 말함, Task에 따라 다시군집화(Clustering)나차원 축소(Dimensionality Reduction)등으로 구분강화학습(Reinforcement Learning)
소프트웨어 에이전트(Agent)가 환경(Environment) 내에서보상(Reward)이 최대화되는 방향으로 행동(Action)을 수행하도록 학습 하는 기법
 학습 중... origin by @oursky.hk
학습 중... origin by @oursky.hk
지도학습, 비지도학습과 강화학습의 정의는 위의 설명과 같으며, 지도학습을 위한 알고리즘은 위에서 말한 Decision Tree나 SVM, Logistic Regression 등이 있고, 비지도학습은 K-Means, KNN, DBSCAN, PCA 등이 있으며, 강화학습은 기본적으로 뉴럴 네트워크(Neural Network)를 기반으로하며 DQN(Deep Q-Networks) 등이 있다.
특히 뉴럴 네트워크, 그러니까 우리가 딥러닝이라 부르는 방법론은 지도학습과 비지도학습, 강화학습까지 모든 Task에서 활용할 수 있으며, 가장 메인스트림을 이루고 있는 지도학습 분야에서도 회귀나 분류를 가리지 않기 때문에, 사실상 현재의 새로운 머신러닝 알고리즘은 딥러닝으로부터 나오기 때문에 머신러닝과 딥러닝이라는 단어를 동일시보는 사람들도 많다.
 사실은 이런걸지도..? origin by @sandserifcomics
사실은 이런걸지도..? origin by @sandserifcomics
딥러닝..??? 🤮
많은 사람들이 알다시피, 딥러닝은 인간(혹은 인지동물)의 뇌 구조를 본떠 만든 인공신경망(Artificical Neural Network)으로 뇌과학과도 긴밀한 관계5를 갖고 있으며, 딥러닝이라는 용어는 딥 뉴럴 네트워크(Deep Neural Network)에서 리브랜딩한 것일 뿐이다.
사실, 딥러닝은 인공지능 역사의 근-본에 가장 가깝다. 딥러닝의 전신인 퍼셉트론(Perceptron)으로부터 실질적인 인공지능의 연구가 시작되었으며, 퍼셉트론은 XOR 문제를 해결하기 위해 다층 퍼셉트론(Multi-Layer Perceptron)으로 발전했고, 긴 기간동안 AI Winter라고 불리는 두 번의 암흑기를 거쳐 현재의 딥러닝이 되었다.
XOR 문제로 처음 퍼셉트론의 허점이 드러나게 되면서 Symbolic AI를 지지하는 사람들이 생겨났고, 인공지능의 학파는 Symbolic AI를 지지하는 쪽과 Non-Symbolic AI, 즉 연결주의(Connectionism)라는 신경망을 지지하는 쪽으로 나뉘게 되었다.
 아 모르겠고 레이어나 더 쌓아
아 모르겠고 레이어나 더 쌓아
최근에서야 컴퓨팅 파워나 빅데이터의 발전으로 딥러닝이 어깨를 피면서 연결주의 학파가 승리했다고 생각하지만, 예전만 해도 신경망 기반으로 AI를 연구한다고 하면 블랙박스를 설명하기도 어려울 뿐더러 지원금도 뚝 끊기기도 해서 설명하기 쉬운 Symbolic AI 쪽이 주를 이루었다고 한다.(존버는 승리한다..?)
그래서, 지금은
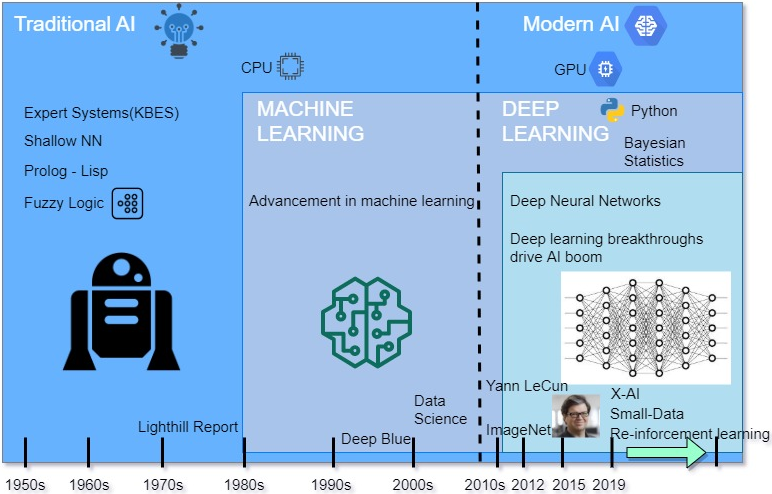 한 눈에 보는 인공지능의 역사 origin by Awais Bajwa
한 눈에 보는 인공지능의 역사 origin by Awais Bajwa
지금은 당연히 딥러닝의 시대다. 인공지능 Task에 대해서 나오는 알고리즘은 모두 딥러닝이고 우승 모델도 다 딥러닝이다. 인공지능 시스템을 위한 생태계(Ecosystem)도 거의 대부분 딥러닝에 최적화 되어 있다. 그럴 수 밖에 없다. 너무 성능의 차이가 압도적이니까. 다른 머신러닝 방법론은 더 이상 메인스트림에 오르지 못한다. 오늘의 모든 방법론은 딥러닝으로부터 비롯된다.
그렇지만 간혹, 다시금 세번째 겨울이 오네마네 하는 소리가 들리곤 한다. 점차 현재의 신경망으로 닿을 수 있는 성능의 한계치에 수렴하는 느낌이 강하고, AGI 같은 범용인공지능을 만들려면 지금의 신경망으로는 턱없이 부족하기 때문이다. 또한, 딥러닝이 블랙박스로 지속되는 한 대중들에게 기술의 신뢰성을 얻어내기는 어려울 것이다.
이러한 상황을 극복하고자 블랙박스를 화이트박스로 만들기 위한 설명 가능한 인공지능(XAI, eXplainable AI)에 대한 연구나 딥러닝에 Symbolic AI를 결합하려는 Neuro-Symbolic AI과 같은 시도가 계속해서 나오고 있다.(물론, 둘다 한참 멀었다고 생각한다.) 그래서 우리는 딥러닝이 발전을 해도 다른 머신러닝 기법이나 선형 대수(Linear Algebra) 컨벡스 최적화(Convex Optimization), 통계적 학습(Statistical Learning)과 같은 기반 지식을 계속해서 공부해야 하나보다..😔
[1] 학습의 방법을 몰랐을 때, 내가 처음 생각한 인공지능의 방법론이다.
[2] 1997년 세계 체스 챔피언을 이긴 IBM Watson 연구소의 Deep Blue도 이러한 방식으로 만들어졌다.
[3] 개인적으로 비지도학습은 궁극적으로 지도학습을 하기 위한 수단이라고 생각한다.
[4] 회귀와 분류는 결과 값이 수치형(Numerical)이냐 범주형(Categorical)이냐의 차이에 따라 구분된다.
[5] 현재까지도 심리학이나 뇌과학 분야에서 딥러닝을 많이 연구하고 있는 것으로 알고 있다.